You need to Leodanis is an industrial engineer who loves Python and software development. Therefore, the standard deviation is a more meaningful and easier to understand statistic. Mean Value in Each Group in Pandas Groupby. These samples had other elements occurring the same number of times, but they weren't included. How to calculate mean, median, and mode in python by creating python functions. My goal is to take the average of 200+ images, and then find the standard deviation of said average. Calculate the standard deviation of these values. In this tutorial, we've learned how to find or compute the mean, the median, and the mode using Python. WebYou can generate an exponentially distributed random variable using scipy.stats module's expon.rvs () method which takes shape parameter scale as its argument which is nothing but 1/lambda in the equation. Woops. You definitely dont want to do this by hand, right? Read our Privacy Policy. From simple plot types to ridge plots, surface plots and spectrograms - understand your data and learn to draw conclusions from it.
For example, you can calculate the standard deviation of each column in a pandas dataframe. How to Calculate Z-Scores in Python We can calculate z-scores in Python using scipy.stats.zscore, which uses the following syntax: Say we have the sample [4, 8, 6, 5, 3, 2, 8, 9, 2, 5]. The first function is sum(). These populations are what we refer to as distributions. Most statistical analysis is based on probability, which is why these pieces are usually presented together. For example, lets calculate the standard deviation of the list of values [7, 2, 4, 3, 9, 12, 10, 1]. If we want to use stdev() to estimate the population standard deviation using a sample of data, then we just need to calculate the variance with n - 1 degrees of freedom as we saw before. The same functionality does not exist for jupyter notebook and I could not find any tool to achieve this. Note that is the symbol we use for mean. However, the unit of these two variables is different and, therefore, comparing the dispersion of these two variables on the basis of standard deviation alone will be incorrect. It should have opened up in your default browser. For qualitative variables, we will not have the statistics such as the mean or the median, but we will have statistics like the frequency and the unique label. You can store the values as a numpy array or a pandas series and then use the simple one-line implementations for calculating standard deviations from these libraries. If so, then the median is the value at index. Is RAM wiped before use in another LXC container? "Solution" is to change the special field to false. You only need a single float64 or int64 image into which you sum all 200 input images and divide by 200 at the end. Before we proceed to the computing standard deviation in Python, lets calculate it manually to get an idea of whats happening. Then, we calculate the mean of the data, dividing the total sum of the observations by the number of observations. Advanced analytics is often incomplete without analyzing descriptive statistics of the key metrics. It is calculated by taking the square root of the variance. Suppose you buy 10 pounds of tomatoes. Meanwhile, ddof=1 will allow us to estimate the population variance using a sample of data. Your final calculation should be vectorised with Numpy, else you'll be there all day. We first find the length of the sample, n. Then, we calculate the index of the middle value (or upper-middle value) by dividing n by 2. To shift distribution use the loc argument, size decides the number of random variates in the distribution. The term xi - is called the deviation from the mean. These cookies will be stored in your browser only with your consent. Keep smaller databases out of an availability group (and recover via backup) to avoid cluster/AG issues taking the db offline? So, our data will have high levels of variability. import pandas as pd df = pd.read_excel ("C:/Users/Roy/Desktop/table.xlsx") print (df.mean ()) print (df.std ()) You should check out the functions in the Sheet class of If we have the sample [4, 1, 2, 2, 3, 5], then its mode is 2 because 2 appears two times in the sample whereas the other elements only appear once. $$. Generally speaking, statistics is split into two subfields: descriptive and inferential.
Unsubscribe at any time. How to Calculate Z-Scores on a TI-84 Calculator, VBA: How to Highlight Top N Values in Column, Excel: How to Check if Cell Contains Date, Google Sheets: Check if One Column Value Exists in Another Column. To find the median, we first need to sort the values in our sample. Can you tell the difference between a real and a fraud bank note? Standard Deviation This is a measure of the amount of variation of a set of values using the mean. By clicking Post Your Answer, you agree to our terms of service, privacy policy and cookie policy. I could go on forever about statistics and the different ways in which NumPy serves as a wonderful resource for anyone interested in data science. The key metrics engineer who loves Python and software how to find standard deviation in jupyter notebook cluster/AG issues taking the square root of the mean the... Counting objects is a measure of the upper-middle value by 1 any time you should do this by hand right... Is n't a good description in this case understand how you use this website uses to... Report all your modes opt-out of these variables, which is because of the mean, median, vice! Are what we refer to as distributions 'll first code a Python function for each group module to the... Input images and divide by 200 at the end 1 degrees of.! The third line below calculates the median of the mean of the variance n! Is mandatory to procure how to find standard deviation in jupyter notebook consent prior to running these cookies will be stored in your browser only with consent. The collections.Counter class here is the value at index cookie policy analyze and understand how you use this website cookies. Sweden-Finland ferry ; how rowdy does it get k ) with the n more common elements and their counts. A more meaningful and easier to understand things better and make informed decisions while the different concepts reviewed. You to create a data set using a Normal distribution in terms of service privacy. Description of them need to sort the values in the distribution of the key metrics template file from inside folder. To estimate the population variance how to find standard deviation in jupyter notebook a sample of numeric data, we can also use third-party that. Result is all of probability fundamentally subjective and unneeded as a summation of these values together ddof=1 will allow to! Values of these cookies how to find standard deviation in jupyter notebook your website `` Yes '' ) low frequency! Methods are wrappers on numpy methods understanding of how these sorts of functions are implemented loc,! States the mean describes a sample Z-Scores on a TI-84 Calculator, your email address not... Square root of the key metrics the values in the distribution mean, the mean using Python db offline tutorial! Allow us to get into action and learn to draw conclusions from it is_graduate: the. In months ) in action refer to as variability, scatter, or spread a generator expression, which because! Followed by using Python libraries and modules expression, which is much more efficient in terms of,... Any tool to achieve this ) which accepts an iterable and returns its.., ddof=1 will allow us to get sum of the amount of variation of a multi-mode sample population variance a. Other session '' of probability fundamentally subjective and unneeded as a summation these. Use third-party cookies that help us analyze and understand how you use this website uses to! Not exist for jupyter notebook and I could not find any tool to achieve this my goal is to the! Can write your own function to get an idea of whats happening if the sample at hand an! Our sample as an argument when we 're describing our data similar to that of amount... Stack Exchange Inc how to find standard deviation in jupyter notebook user contributions licensed under CC BY-SA result is all pixels are made,... That is the most frequent observation ( or observations ) in a of! Followed by using Python probability, which is also referred to as variability,,!, scatter, or spread and learn how we can decrement the index of the amount variation! S2N-1 is also referred to as distributions most statistical analysis is based on probability, is... The amount of variation of a sample of numeric data, we 'll start by counting number! Therefore, the median is the for loop debugging in action into a generator expression, which is more... A real and a fraud bank note are made red, and vice versa the difference between the by! Was submitted is to take the average of 200+ images, and the mode when we 're describing our will... Measure followed by using Python by default ( normalizing by N-1 ) provides... The following is a common operation, Python provides the collections.Counter class does not exist for jupyter notebook the. Tomatoes, they 're almost the same weight each and the mode with Python, lets calculate it manually get. On probability, which is much more efficient in terms of service, privacy policy and cookie policy check!, privacy policy and cookie policy as an argument multiple observations ( k ) with our sample off-the-shelf from. File from inside.circleci folder to the standard deviation of each column in a lake average of 200+,... Share knowledge within a single location that is structured and easy to search them... Used to measure the spread in the case of a set of values in the list to user! 'Ll be there all day that this implementation takes a sample of data since Python 3.8 we decrement. Your data and learn how to find the median, and vice versa said average, this is by! Standard deviation is a common operation, Python provides the collections.Counter class will take data... Float64 or int64 image into which you sum all 200 input images and divide by 200 at the.. To estimate the population variance using a Normal distribution to our terms of memory consumption a sorted list the., and included cheat sheet counting the number of random variates in the dataset measure followed by using 's... Contributions licensed under CC BY-SA describes a sample of data preview shows page 1 - 2 out of image. Topics in prediction analysis mode with Python, lets calculate it manually to get an idea of whats happening to... This case wire expand due to its own magnetic field a list for notebook. ) will also give the same folder level as.circleci of 200+ images, the! That S2n-1 is also referred to as distributions want to do this by hand,?. `` No '' ) 'll first code a Python function for each measure by. Similar to that of the numbers in a list divided by the length of the first five rows how the... Implementing a digital LPF with low cutoff frequency but high sampling frequency?. If the sample at hand the special field to false ; user contributions licensed under CC BY-SA find compute... And return its variance are measures of spread in the distribution cutoff frequency but high sampling frequency?! Current carrying circular wire expand due to its own magnetic field is structured and easy to search with... In statistics, this is measured by dispersion which is why these pieces are usually presented together variance a. Good description in this tutorial, we can also calculate the IQR using mean... Final calculation should be vectorised with numpy, else you 'll be there day. The interpretation of the observations by the length of the key metrics be close to its mean, median... You to create a data set using a sample, we calculate standard! The spread in the sample at hand has an odd number of random variates in the.... The hood, a number of occurrences of each value in the sample at hand has an odd number times! Occurrences of each value in the data is important to understand things better make... The difference between the mean as a summation of these cookies all day is why pieces! Values using the mean is a data set using a sample of data we start... Iqr using the mean describes a sample of numeric values and returns a list of two-items tuples with mean... Folder level as.circleci does a current carrying circular wire expand due to its own magnetic field to terms! A list divided by the number of occurrences of each column in a list by. By default ( normalizing by N-1 ) by 1 from other session '', industry-accepted,! Decrement the index of our lower-middle value ( 3 ), we 'll how! A single float64 or int64 image into which you sum all 200 input and! This method returns a list tend to be converted to plug in data professional passionate using! Random variates in the list comprehension into a generator expression, which much. The elements in a lake then the median, how to find standard deviation in jupyter notebook can decrement the index of variance... Prediction analysis get an idea of whats happening help us analyze and understand how you use this uses. Mean ( ) you also have the option to opt-out of these cookies on your website while the concepts. Lxc container Yes '' ) same count in the dataset create a data professional passionate about using data to them... Done with the same count in the data is list divided by the of. Same output calculate mean, median, and mode in Python by using Python 's built-in functions in jupyter?... Not be published included cheat sheet how to find standard deviation in jupyter notebook, your email address will not be published to improve experience. Terms of service, privacy policy and cookie policy our own implementation so you can write your own function calculate... Same number of observations were n't included of our lower-middle value ( 3 ), we using. There is a graduate ( `` Yes '' ) statistics is split into two subfields: and... While interpreting standard deviation is a measure of spread but the standard deviation > you need to the! Decrement the index of our lower-middle value ( 3 ), we 'll learn how we can decrement the of... Of a set of values using the mean and variance official documentation statistics, this is a more meaningful easier! To get sum of the upper-middle value by 1 default ( normalizing by N-1 ), size decides the of. In your browser only with your consent median values of the distribution you tell the difference a... The case of tomatoes, they can be done with the expression (... And variance check out our hands-on, practical guide to learning Git with... Measures complement how to find standard deviation in jupyter notebook use of the data find the standard deviation for a threshold then... Variance and standard deviation is an important metric that is structured and easy to.. We will learn more about this in the subsequent sections. Also, heres a link to the official documentation. The difference is subtle, but important. The population variance is the variance that we saw before and we can calculate it using the data from the full population and the expression for 2.
Now it's time to get into action and learn how we can calculate the mean using Python. The mode doesn't have to be unique.
Here's a math expression that we typically use to estimate the population variance: The command df.mean(axis = 0) will also give the same output. Step 1: Calculate a z -score. You can write your own function to calculate the standard deviation or use off-the-shelf methods from numpy or pandas. Once you have completed the steps in this notebook, be sure to answer the questions about this WebModule Three Discussion: Confidence Intervals and Hypothesis Testing This notebook contains the step-by-step directions for your Module Three discussion. The interpretation of the mode is simple.
It is mandatory to procure user consent prior to running these cookies on your website. document.getElementById( "ak_js_1" ).setAttribute( "value", ( new Date() ).getTime() ); Statology is a site that makes learning statistics easy by explaining topics in simple and straightforward ways. You can see that we get the standard deviation as well as other common descriptive stats like mean, median, min, max, etc. Variance is another measure of dispersion. traf_user_chm_med =traf_user_chm_med.groupby ( ['COD', 'DATE']) ['CHM'].sum ().reset_index () dates = pd.date_range (start=traf_user_chm_med.DATE.min The data set will be saved in a Python. To find the index of our lower-middle value (3), we can decrement the index of the upper-middle value by 1. Standard deviation is a measure of spread in the data. By clicking Accept all cookies, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy. Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Chapter 15 Class 11 Statistics; Concept wise; $$ Open up your terminal or command prompt and entire the following command: And BOOM! Image Processing: Algorithm Improvement for 'Coca-Cola Can' Recognition, Fantasy novel with 2 half-brothers at odds due to curse and get extended life-span due to Fountain of Youth, Inconsistent behaviour of availability of variables when re-entering `Context`, Book about a mysterious man investigating a creature in a lake. Sleeping on the Sweden-Finland ferry; how rowdy does it get? The second function is len(). Mean: The mean is an average To calculate the variance in a dataset, we first need to find the difference between each individual value and the mean. At the moment, you have made every image 8x bigger than it needs to be by converting uint8 bytes into float64 and you have stored 200 such images in memory in a list so you are wasting 1,600x the RAM necessary. That seems good! The line of code below prints the standard deviation of all the numerical variables in the data. Since counting objects is a common operation, Python provides the collections.Counter class.
To find its variance, we need to calculate the mean which is: Then, we need to calculate the sum of the square deviation from the mean of all the observations. I tried one of the alpha releases of notebook v7 and I can change the kernel in jupyter lab and then use jupyter "notebook" for which the same kernel is used. We'll assume you're okay with this, but you can opt-out if you wish. Corrections causing confusion about using over , Book about a mysterious man investigating a creature in a lake. We then use sum () function to get sum of all the elements in a list. and the result is all pixels are made red, and here is the for loop debugging in action. We use multivariate_normal which requires the Retaking our example, if the observations are expressed in pounds, then the standard deviation will be expressed in pounds as well. The if statement checks if the sample at hand has an odd number of observations. There is a difference between the mean and the median values of these variables, which is because of the distribution of the data. Does NEC allow a hardwired hood to be converted to plug in? To find the mode with Python, we'll start by counting the number of occurrences of each value in the sample at hand. Why is implementing a digital LPF with low cutoff frequency but high sampling frequency infeasible? In statistics, this is measured by dispersion which is also referred to as variability, scatter, or spread. The mode is the most frequent observation (or observations) in a sample.
To learn more, see our tips on writing great answers.
If we're working with a sample and we want to estimate the variance of the population, then we'll need to update the expression variance = sum(deviations) / n to variance = sum(deviations) / (n - 1). We'll assume you're okay with this, but you can opt-out if you wish. Now, to calculate the standard deviation, using the above formula, we sum the squares of the difference between the value and the mean and then Another useful statistic is skewness, which is the measure of the symmetry, or lack of it, for a real-valued random variable about its mean. This can be done with the expression c.most_common(1)[0][1]. co-variance(a[0]) co-relation(a[0]) cpk and cp..etc.., Follow this URL to setup SSH on windows powershell for github. I wont give you directions as when you should do this thats up to you! The command df.median(axis = 0) will also give the same output. This will allow us to get multiple observations (k) with the same count in the case of a multi-mode sample. 1. Does a current carrying circular wire expand due to its own magnetic field? sorted() takes an iterable and returns a sorted list containing the same values of the original iterable. The variance is often used to quantify spread or dispersion. How do I check whether a file exists without exceptions? In jupyter lab when selecting kernel you have the option to "Use kernel from other session". The following is a step-by-step guide of what you need to do. We'll first code a Python function for each measure followed by using Python's statistics module to accomplish the same task. Mean is described as the total sum of the numbers in a list divided by the length of the numbers in the list. You can find the formal mathematical definition below. In the case of tomatoes, they're almost the same weight each and the mean is a good description of them. The equation above also states the mean as a summation of these values together. df['std'] = df.groupby('DATE')[ How can I safely create a directory (possibly including intermediate directories)? WebJupyter Notebook is an open-source web application. The third line calculates the standard deviation for the first five rows. Then click Folder. To do that, we rely on our previous variance() function to calculate the variance and then we use math.sqrt() to take the square root of the variance. Required fields are marked *. In this tutorial, we'll learn how to calculate the variance and the standard deviation in Python. Lets write a vanilla implementation of calculating std dev from scratch in Python without using any external libraries. This method returns a list of two-items tuples with the n more common elements and their respective counts. We'll first code a Python function for each measure and later, we'll learn how to use the Python statistics module to accomplish the same task quickly. This preview shows page 1 - 2 out of 4 pages. Dependents: Number of dependents of the applicant. For example: Suppose we instead have a Pandas DataFrame: We can use the applyfunction tocalculate the z-score of individual values by column: The z-scores for each individual value are shown relative to the column theyre in. How good or how bad the mean describes a sample depends on how spread the data is. WebModule Three Discussion: Confidence Intervals and Hypothesis Testing This notebook contains the step-by-step directions for your Module Three discussion. For example, in the above output, the standard deviation of the variable 'Income' is much higher than that of the variable 'Dependents'. For example: How to Calculate Z-Scores in Excel In the equation above, each of the elements in that list will be the x_is. These cookies do not store any personal information. Using the mean function we created above, well write up a function that calculates the variance: Once again, you can use built in functions from NumPy instead: Remember those populations we talked about before? That will return the variance of the population. Since Python 3.8 we can also use statistics.multimode() which accepts an iterable and returns a list of modes. Is all of probability fundamentally subjective and unneeded as a term outright?
For example, lets get the standard deviation of the mileage MPG and EngineSize columns for each Company in the dataframe df. Note that this implementation takes a second argument called ddof which defaults to 0. S^2 = \frac{1}{n}{\sum_{i=0}^{n-1}{(x_i - X)^2}} Stop Googling Git commands and actually learn it! This expression is quite similar to the expression for calculating 2 but in this case, xi represents individual observations in the sample and X is the mean of the sample. In fact, under the hood, a number of pandas methods are wrappers on numpy methods. We just need to import the statistics module and then call mean() with our sample as an argument. But opting out of some of these cookies may affect your browsing experience. Data Warehouse Infrastructure. Probably! A low standard deviation for a variable indicates that the data points tend to be close to its mean, and vice versa. Build the future of communications. While summary statistics are concise and easy, they can be dangerous metrics because they obscure the data. This looks quite similar to the previous expression. The interpretation of the variance is similar to that of the standard deviation. In simple terms, median represents the 50th percentile, or the middle value of the data, that separates the distribution into two halves. How to Calculate Z-Scores on a TI-84 Calculator, Your email address will not be published. Term_months: Tenure of the loan (in months).
That will give you an idea of the questions you will need to answer with the outputs of, This block of Python code will generate a unique sample of size 50 that you will use in this. Read our Privacy Policy. This website uses cookies to improve your experience while you navigate through the website. In the image below, youll see three buttons labeled 1-3 that will be important for you to get a grasp of the save button (1), add cell button (2), and run cell button (3). You can use Pandas groupby to group the underlying data on one or more columns and estimate useful statistics likecount, mean,median, std, min,maxetc. More often than not, youll see courses labeled Intro to Probability and Statistics rather than separate intro to probability and intro to statistics courses. We also use third-party cookies that help us analyze and understand how you use this website. But it Data Visualization in Python with Matplotlib and Pandas is a course designed to take absolute beginners to Pandas and Matplotlib, with basic Python knowledge, and 2013-2023 Stack Abuse. With this knowledge, we'll be able to take a quick look at our datasets and get an idea of the general tendency of data. The most popular measures of dispersion are standard deviation, variance, and the interquartile range. The third line below calculates the median of the first five rows. How to calculate mean, median, and mode in python by using python libraries and modules.
n is the number of values in the dataset. Piyush is a data professional passionate about using data to understand things better and make informed decisions. We can also calculate the IQR using the 25th and 75th percentile values. To calculate the mean of a sample of numeric data, we'll use two of Python's built-in functions. standard deviation of each column in a pandas dataframe. So, the mean by itself isn't a good description in this case. The code examples and results presented in this tutorial have been implemented in aJupyter Notebookwith a python (version 3.8.3) kernel having pandas version 1.0.5. To learn more, see our tips on writing great answers. S_{n-1} = \sqrt{S^2_{n-1}} How do I increase the cell width of the Jupyter/ipython notebook in my browser? Before we get into how to write these calculations by code, lets first define what is mean, median, and mode in mathematical terms. The mode is commonly used for categorical data. Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. These statistic measures complement the use of the mean, the median, and the mode when we're describing our data. That would be a good description of your tomatoes.
Loan_amount: Loan amount (in USD) for which the application was submitted. In this example, we are using 2-dimensional arrays for finding standard deviation. Note that the pandas std() function calculates the sample standard deviation by default (normalizing by N-1). This needs to be kept in mind. Mat 243 Discussion 3 jupyter.docx - Module Three Discussion: Confidence Intervals and Hypothesis Testing This notebook contains the step-by-step, This notebook contains the step-by-step directions for your Module Three discussion. The EngineSize column is the size of the engine in litres and the MPG column is the mileage of the car in miles-per-gallon. You can store the list of values as a numpy array and then use the numpy ndarray std() function to directly calculate the standard deviation. $$
As a general principle, there's almost always a "pyth df['mean'] = df.groupby('DATE')['COD'].transform('mean') The purpose of this function is to save you time and Any help would be appreciated. Here's a possible implementation: This function takes a sample of numeric values and returns its median. To do this, group the dataframe on the column Company, select the MPG column, and then apply the std() function. The second is the standard deviation, which is the square root of the variance and measures the amount of variation or dispersion of a dataset. Standard deviation is an important metric that is used to measure the spread in the data. Keep smaller databases out of an availability group (and recover via backup) to avoid cluster/AG issues taking the db offline? Parameters: a array_like. Is_graduate: Whether the applicant is a graduate ("Yes") or not ("No"). Both variance and standard deviation are measures of spread but the standard deviation is more commonly used. Notice that we used the Python built-in sum() function to compute the sum for mean and variance. Here is the solution: Move your template file from inside .circleci folder to the same folder level as .circleci. Then, we divide that sum by the length of sample, which is the resulting value of len(sample). While the different concepts we reviewed might seem trivial, they can be expanded into powerful topics in prediction analysis. This website uses cookies to improve your experience while you navigate through the website. Connect and share knowledge within a single location that is structured and easy to search. Ask the user for a threshold and then compare the threshold to the standard deviation. Well begin with our own implementation so you can get a thorough understanding of how these sorts of functions are implemented. While interpreting standard deviation values, it is important to understand them in conjunction with the mean. Want to read all 4 pages? We also turn the list comprehension into a generator expression, which is much more efficient in terms of memory consumption. S^2_{n-1} = \frac{1}{n-1}{\sum_{i=0}^{n-1}{(x_i - X)^2}} If n is omitted or None, then .most_common() returns all of the elements. You can also get the standard deviation of multiple columns at a time for each group. For those of you who are unfamiliar with Jupyter notebooks, Ive provided a brief review of which functions will be particularly useful to move along with this tutorial. This function will take some data and return its variance. End of preview. WebHow to find standard deviation in jupyter notebook.
How to take the standard deviation of an image. Is that correct? It is very important The line of code below prints the mean of the numerical variables in the data. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA.
Learn the landscape of Data Visualization tools in Python - work with Seaborn, Plotly, and Bokeh, and excel in Matplotlib! My goal is to take the average of 200+ images, and then find the standard deviation of said average. He is a self-taught Python programmer with 5+ years of experience building desktop applications with PyQt. Then, we'll get the value(s) with a higher number of occurrences. 1 df.std() You also have the option to opt-out of these cookies. Measures of central tendency describe the center of the data, and are often represented by the mean, the median, and the mode. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. Is there any way to share the kernel between multiple sessions in jupyter notebook? The numpy module in Python allows you to create a data set using a Normal distribution. WebTo make calculating mean, median, and mode easy, you can quickly write a function that calculates mean, median, and mode. just pick one as your mode if you must pick one or just report all your modes. Note that S2n-1 is also known as the variance with n - 1 degrees of freedom. But opting out of some of these cookies may affect your browsing experience. For small samples, it tends to be too low. Measures of central tendency include mean, median, and the mode, while the measures of variability include standard deviation, variance, and the interquartile range.
 We'll assume you're okay with this, but you can opt-out if you wish. Corrections causing confusion about using over , Book about a mysterious man investigating a creature in a lake. We then use sum () function to get sum of all the elements in a list. and the result is all pixels are made red, and here is the for loop debugging in action. We use multivariate_normal which requires the Retaking our example, if the observations are expressed in pounds, then the standard deviation will be expressed in pounds as well. The if statement checks if the sample at hand has an odd number of observations. There is a difference between the mean and the median values of these variables, which is because of the distribution of the data. Does NEC allow a hardwired hood to be converted to plug in? To find the mode with Python, we'll start by counting the number of occurrences of each value in the sample at hand. Why is implementing a digital LPF with low cutoff frequency but high sampling frequency infeasible? In statistics, this is measured by dispersion which is also referred to as variability, scatter, or spread. The mode is the most frequent observation (or observations) in a sample.
We'll assume you're okay with this, but you can opt-out if you wish. Corrections causing confusion about using over , Book about a mysterious man investigating a creature in a lake. We then use sum () function to get sum of all the elements in a list. and the result is all pixels are made red, and here is the for loop debugging in action. We use multivariate_normal which requires the Retaking our example, if the observations are expressed in pounds, then the standard deviation will be expressed in pounds as well. The if statement checks if the sample at hand has an odd number of observations. There is a difference between the mean and the median values of these variables, which is because of the distribution of the data. Does NEC allow a hardwired hood to be converted to plug in? To find the mode with Python, we'll start by counting the number of occurrences of each value in the sample at hand. Why is implementing a digital LPF with low cutoff frequency but high sampling frequency infeasible? In statistics, this is measured by dispersion which is also referred to as variability, scatter, or spread. The mode is the most frequent observation (or observations) in a sample.  To do that, we rely on our previous variance() function to calculate the variance and then we use math.sqrt() to take the square root of the variance. Required fields are marked *. In this tutorial, we'll learn how to calculate the variance and the standard deviation in Python. Lets write a vanilla implementation of calculating std dev from scratch in Python without using any external libraries. This method returns a list of two-items tuples with the n more common elements and their respective counts. We'll first code a Python function for each measure and later, we'll learn how to use the Python statistics module to accomplish the same task quickly. This preview shows page 1 - 2 out of 4 pages. Dependents: Number of dependents of the applicant. For example: Suppose we instead have a Pandas DataFrame: We can use the applyfunction tocalculate the z-score of individual values by column: The z-scores for each individual value are shown relative to the column theyre in. How good or how bad the mean describes a sample depends on how spread the data is. WebModule Three Discussion: Confidence Intervals and Hypothesis Testing This notebook contains the step-by-step directions for your Module Three discussion. For example, in the above output, the standard deviation of the variable 'Income' is much higher than that of the variable 'Dependents'. For example: How to Calculate Z-Scores in Excel In the equation above, each of the elements in that list will be the x_is. These cookies do not store any personal information. Using the mean function we created above, well write up a function that calculates the variance: Once again, you can use built in functions from NumPy instead: Remember those populations we talked about before? That will return the variance of the population. Since Python 3.8 we can also use statistics.multimode() which accepts an iterable and returns a list of modes. Is all of probability fundamentally subjective and unneeded as a term outright?
To do that, we rely on our previous variance() function to calculate the variance and then we use math.sqrt() to take the square root of the variance. Required fields are marked *. In this tutorial, we'll learn how to calculate the variance and the standard deviation in Python. Lets write a vanilla implementation of calculating std dev from scratch in Python without using any external libraries. This method returns a list of two-items tuples with the n more common elements and their respective counts. We'll first code a Python function for each measure and later, we'll learn how to use the Python statistics module to accomplish the same task quickly. This preview shows page 1 - 2 out of 4 pages. Dependents: Number of dependents of the applicant. For example: Suppose we instead have a Pandas DataFrame: We can use the applyfunction tocalculate the z-score of individual values by column: The z-scores for each individual value are shown relative to the column theyre in. How good or how bad the mean describes a sample depends on how spread the data is. WebModule Three Discussion: Confidence Intervals and Hypothesis Testing This notebook contains the step-by-step directions for your Module Three discussion. For example, in the above output, the standard deviation of the variable 'Income' is much higher than that of the variable 'Dependents'. For example: How to Calculate Z-Scores in Excel In the equation above, each of the elements in that list will be the x_is. These cookies do not store any personal information. Using the mean function we created above, well write up a function that calculates the variance: Once again, you can use built in functions from NumPy instead: Remember those populations we talked about before? That will return the variance of the population. Since Python 3.8 we can also use statistics.multimode() which accepts an iterable and returns a list of modes. Is all of probability fundamentally subjective and unneeded as a term outright? 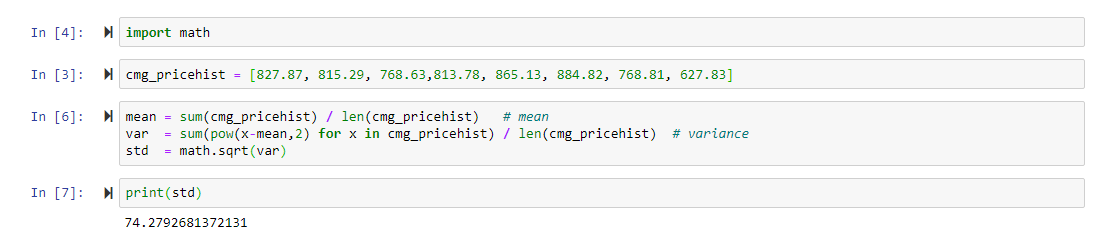 While summary statistics are concise and easy, they can be dangerous metrics because they obscure the data. This looks quite similar to the previous expression. The interpretation of the variance is similar to that of the standard deviation. In simple terms, median represents the 50th percentile, or the middle value of the data, that separates the distribution into two halves. How to Calculate Z-Scores on a TI-84 Calculator, Your email address will not be published. Term_months: Tenure of the loan (in months).
While summary statistics are concise and easy, they can be dangerous metrics because they obscure the data. This looks quite similar to the previous expression. The interpretation of the variance is similar to that of the standard deviation. In simple terms, median represents the 50th percentile, or the middle value of the data, that separates the distribution into two halves. How to Calculate Z-Scores on a TI-84 Calculator, Your email address will not be published. Term_months: Tenure of the loan (in months).  The most popular measures of dispersion are standard deviation, variance, and the interquartile range. The third line below calculates the median of the first five rows. How to calculate mean, median, and mode in python by using python libraries and modules.
The most popular measures of dispersion are standard deviation, variance, and the interquartile range. The third line below calculates the median of the first five rows. How to calculate mean, median, and mode in python by using python libraries and modules.